
How To Scrape Reddit Comments
Quick tutorial on using PRAW to scrape all comments in a Reddit thread

In several my projects, I perform text analysis on Reddit comments. This is a brief guide on my data extraction process using PRAW. It is designed to help others who want to play around with the Reddit data or future me when I inevitably forget how to do all this. I ran everything in a Google Colab notebook, but feel free to use whatever you prefer.
What is PRAW
PRAW stands for ‘Python Reddit API Wrapper’. It is a Python module that provides a simple access to Reddit’s API. It lets us grab all sorts of interesting data from the platform, including comments.
Step 1: Setting Up PRAW
PRAW can be installed using pip.
!pip install prawOnce installed, we can load the library into the document for use.
import prawStep 2: Creating a Reddit Instance
Every call begins with an initialisation of a Reddit instance, which we can do using the code below. If you have all your authentication information ready, skip to step 4.
reddit = praw.Reddit(
client_id = [YOUR CLIENT ID],
client_secret = [YOUR CLIENT SECRET],
user_agent = [YOUR USER AGENT],
username = [YOUR USERNAME],
password = [YOUR PASSWORD],
)Step 3: Getting Authenticated
A Reddit instance requires several pieces of information for authentication.
Some of them are pretty straightforward. username and password are your login credentials for your Reddit account. user_agent is just an identifier and can be absolutely anything (as long as it is in string format).
For client_id and client_secret, you will have to create a reddit app by navigating to this page and pressing the button labeled create an app or create another app.
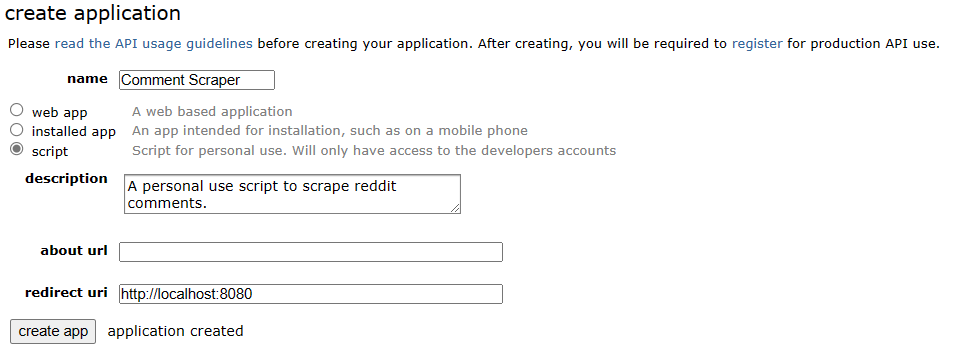
This will open a form where you need to fill in a name, description and redirect uri. The name and description are for your own use and can be anything. I recommend something descriptive. However, you should enter http://localhost:8080 for the redirect uri.
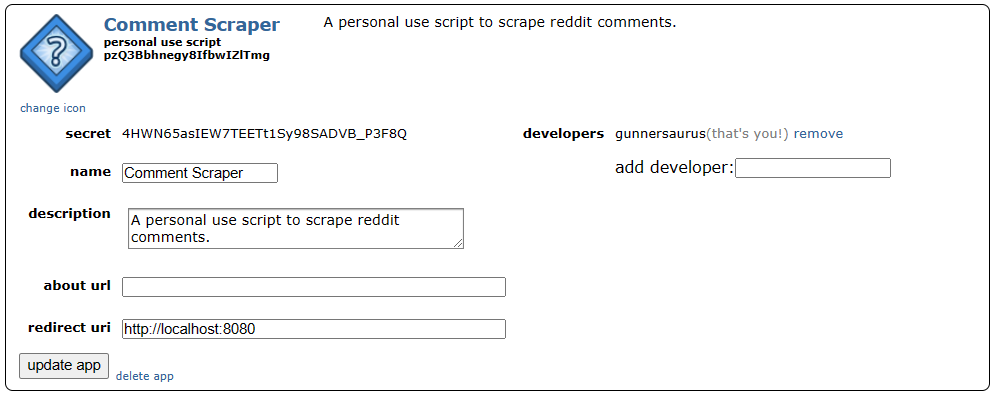
After pressing create app, a new application will appear. client_id is the string listed just under personal use script and client_secret is the string adjacent to secret. The credentials in this picture have been edited, so don’t even try.
Step 4: Creating a Submission Object
Now that we are authenticated and have a Reddit instance, we can start accessing the data, which is stored in objects. Comments can be navigated through the submission object.
We can create a submission object by using the either entire URL or the submissions ID that comes after comments/ in the URL.
submission = reddit.submission('https://www.reddit.com/r/Gunners/comments/11h3vxt/saka_and_emile_smith_rowe/')
submission = reddit.submission('11h3vxt')Step 5: Accessing Comments
With a submission object we can then interact with its CommentForest through the submission’s Submission.comments attribute. A CommentForest is a list of top-level comments each of which contains a CommentForest of replies.
The code below flattens all comments and prints out each one.
submission.comments.replace_more(limit=None)
for comment in submission.comments.list():
print(comment.body)Step 6: A Function For Everything
The code below creates a function that ties everything together. The function takes in a URL, creates a submission object from it, loops through the comments, and puts everything into a pandas data frame.
Notice that the function extracts some additional metadata in addition to the contents of the comment (number of awards, score, controversiality, and author).
import pandas as pd
def getComments(url):
# create submission object
submission = reddit.submission(url)
#create empty list
comments_list = []
# loop through comments and append each to list
submission.comments.replace_more(limit=None)
for comment in submission.comments.list():
comments_list.append([comment.total_awards_received,
comment.score,
comment.controversiality,
comment.author,
comment.body])
# convert list to dataframe
df = pd.DataFrame(comments_list)
# rename columns
df.columns = ['numawards','score','controversiality','author','content']
return dfRunning the command below should yield a data frame populated with comments data.
getComments('11h3vxt')Conclusions
That’s all folks. Run all the code chunks above and you should end up with a pretty neat dataset to explore.